
- 0
- 837 words
In today’s digital world, the rapid growth of Artificial Intelligence (AI) and Big Data has transformed how we live, work, and make decisions. From personalized recommendations on streaming platforms to real-time fraud detection in banking, these technologies rely heavily on processing massive amounts of data quickly and efficiently. This is where Distributed and Parallel Computing step in as the backbone of modern computing systems. Without them, handling such complex and large-scale tasks would be nearly impossible.
Understanding Distributed Computing
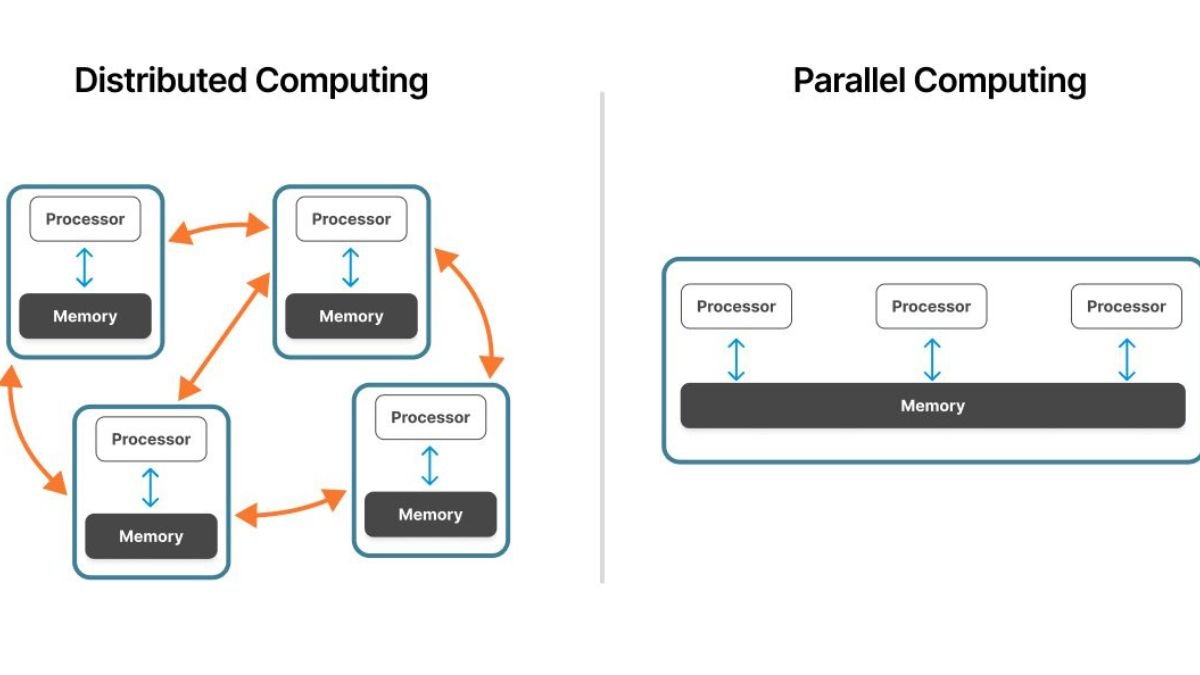
Distributed computing refers to a system where multiple computers, often located in different geographical areas, work together to achieve a common goal. Instead of relying on a single powerful machine, tasks are divided and distributed across several systems. Each system performs its part of the task, and the results are combined to produce the final output.
This approach offers several advantages, including scalability, reliability, and efficiency. For example, when a company processes user data from millions of customers worldwide, distributed systems allow the workload to be shared across multiple servers, reducing processing time and preventing system overload. It also ensures that if one system fails, others can continue functioning, making the overall system more resilient.
What is Parallel Computing?
Parallel computing, on the other hand, focuses on performing multiple calculations or processes simultaneously within a single system or across multiple processors. Instead of executing tasks one after another, parallel computing breaks them into smaller sub-tasks that can run at the same time.
This significantly improves speed and performance, especially for data-intensive applications. For instance, training an AI model requires processing enormous datasets. By using parallel computing, these tasks can be handled simultaneously, reducing training time from days to hours or even minutes.
Role in Artificial Intelligence
Artificial Intelligence relies on large datasets and complex algorithms to learn and make decisions. Training machine learning models involves repeated calculations and adjustments, which demand immense computational power. Distributed and parallel computing make this possible by dividing the workload and processing it efficiently.
In AI applications such as image recognition, natural language processing, and autonomous systems, these computing methods enable faster data processing and real-time responses. Without them, AI systems would struggle to keep up with the growing demand for speed and accuracy. They also allow researchers and developers to experiment with larger models and more sophisticated techniques, pushing the boundaries of what AI can achieve.
Importance for Big Data
Big Data refers to extremely large datasets that cannot be processed using traditional methods. These datasets come from various sources, including social media, sensors, transactions, and more. Managing and analyzing such data requires powerful computing solutions.
Distributed computing helps store and manage data across multiple systems, making it easier to handle large volumes. Parallel computing accelerates data processing by analyzing multiple data points simultaneously. Together, they enable organizations to extract valuable insights quickly, helping in better decision-making, predictive analysis, and improved business strategies.
For example, companies use these technologies to analyze customer behavior, optimize supply chains, and detect patterns that would otherwise remain hidden. This capability is crucial in today’s competitive environment, where data-driven decisions can make a significant difference.
Real-World Applications
The impact of distributed and parallel computing can be seen in various real-world applications. Streaming services use these technologies to deliver content seamlessly to millions of users at once. Financial institutions rely on them for real-time transaction processing and fraud detection. Healthcare systems use them to analyze patient data and support advanced research.
Even everyday technologies like search engines and navigation systems depend on these computing methods to provide accurate and fast results. As the demand for data processing continues to grow, their importance will only increase.
Challenges and Future Scope
Despite their advantages, distributed and parallel computing also come with challenges. Managing multiple systems, ensuring data security, and maintaining synchronization between processes can be complex. Additionally, designing efficient algorithms that fully utilize these systems requires specialized knowledge.
However, advancements in cloud computing and modern frameworks are making it easier to implement these technologies. The future looks promising, with continued innovation expected to enhance performance, reduce costs, and simplify implementation. As AI and Big Data continue to evolve, the role of these computing methods will become even more critical.
Conclusion
Distributed and Parallel Computing are essential pillars supporting the growth of AI and Big Data. They provide the speed, scalability, and efficiency needed to process vast amounts of information in real time. As technology continues to advance, their importance will only grow, enabling smarter systems, faster insights, and more innovative solutions. Embracing these computing methods is not just an option but a necessity for anyone looking to thrive in the data-driven world of today and tomorrow.
Author
fouzik457@gmail.com
Related Posts
Computer Vision and Image Processing: Applications in Healthcare & Industry
- 0
- 767 words
In today’s digital world, Computer Vision and Image Processing have emerged as technologies evolving at a pace far exceeding our imagination. These...
Read out all
How Machine Learning is Changing Real-World Solutions in 2025
- 0
- 1,233 word
Machine learning (ML), a powerful branch of artificial intelligence, is no longer confined to research labs or tech giants. In 2025, it...
Read out all
Cybersecurity in the Age of AI: Protecting Data in 2025 and Beyond
- 0
- 648 words
With the advent of technology, everything is performed on the internet, making the need for cybersecurity more crucial than ever. Moreover, with...
Read out all
Blockchain Technology in Computer Science: Beyond Cryptocurrency
- 0
- 742 words
While the use of blockchain technology is predominantly associated with digital currencies, in reality, the technology has much wider implications than just...
Read out all
10 Key Artificial Intelligence Trends Shaping 2025 with Research Data
- 0
- 1,097 word
Artificial Intelligence (AI) is no longer just a futuristic concept—it has become a powerful force shaping how we live, work, and interact...
Read out all
Internet of Things (IoT) and AI Integration: Smart Future Explained
- 0
- 646 words
Today’s world is rapidly advancing toward digital transformation, where everything is becoming interconnected via the internet. The Internet of Things (IoT) and...
Read out all